Trending Content




The $6-billion Azeri Central East (ACE) platform is the first BP-operated offshore production facility controlled from onshore.

Kampala is drawing now on international experience to sidestep the “oil curse” before first crude flows from its Lake Albert developments.

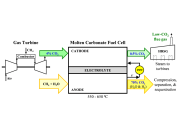
The project will implement two distinct carbon technologies aimed at capturing and storing carbon dioxide. Svante’s CEO Claude Letourneau describes his company’s solid-sorbent technology used in collaboration with Climeworks, one of the awarded companies.
-
 Independent producer divests interest in Buckskin field along with stakes in a pair of LLOG-led discoveries.
Independent producer divests interest in Buckskin field along with stakes in a pair of LLOG-led discoveries. -
The new vessels bring QatarEnergy’s fleet to 104 as the company ramps up production with its North Field expansion.
-
The US supermajor aims to speed the commercialization of a new liquid solvent that strips carbon dioxide from industrial flue gas.



Get JPT articles in your LinkedIn feed and stay current with oil and gas news and technology.

From the first supercomputer to generative AI, JPT has followed the advancement of digital technology in the petroleum industry. As the steady march of innovation continues, four experts give their views on the state and future of data science in the industry.

There will always be a need for good artificial lift engineers. So, what should the next generation of its professionals be trying to pursue?

Longtime leaders in artificial lift discuss and share their insights on the rapidly evolving segment’s past, present, and future.

The world of artificial lift has witnessed a remarkable revolution over the past 25 years, with many of the events and technology trends recorded in the Journal of Petroleum Technology.

Longtime JPT Technology Editor Dennis Denney discusses his career at SPE and the development of the magazine’s Technology Focus feature.

We’re excited to begin the year with the commemoration of JPT’s 75th anniversary. This issue launches our special features dedicated to JPT’s reporting of technology and practices over the past 7½ decades.

Highlights of innovations in fracturing, drilling, and reservoir engineering include mysterious gummy bears, horseshoe-shaped wells, and automated rigs.

Find out what made the list of big technology breakthroughs that have shaped the oil and gas industry over the past quarter century.

The topics covered in JPT’s Technology Focus feature span the breadth of the upstream industry. A review of these topics over the years illustrates the changes that have affected E&P professionals.
-
 A 44-well development tests what ConocoPhillips has learned about maximizing the value of the wells by figuring out how they drain the reservoir.
A 44-well development tests what ConocoPhillips has learned about maximizing the value of the wells by figuring out how they drain the reservoir. -
 Jennifer L. Miskimins is the nominee for 2026 SPE President. She and six others make up the new slate of nominees recommended for positions open on the SPE International Board of Directors.
Jennifer L. Miskimins is the nominee for 2026 SPE President. She and six others make up the new slate of nominees recommended for positions open on the SPE International Board of Directors. -
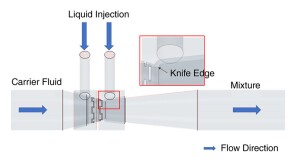
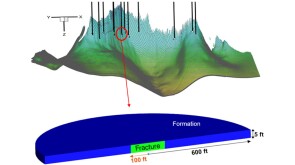
 To avoid costly interventions like sidetracking or wellbore abandonment, a check-valve system was installed near the sandface within three injector wells which prevented the mobilization of fines from the reservoir into the wellbore by stopping backflow.
To avoid costly interventions like sidetracking or wellbore abandonment, a check-valve system was installed near the sandface within three injector wells which prevented the mobilization of fines from the reservoir into the wellbore by stopping backflow. -
 The challenges that geothermal energy faces to become a leading player in the net-zero world are well within the areas of expertise of the SPE community, ranging from rapid technology implementation and learning-by-doing to assure competitiveness to establishing suitable funding mechanisms to secure access to capital.
The challenges that geothermal energy faces to become a leading player in the net-zero world are well within the areas of expertise of the SPE community, ranging from rapid technology implementation and learning-by-doing to assure competitiveness to establishing suitable funding mechanisms to secure access to capital.
Access to JPT Digital/PDF/Issue

Sign Up for JPT Newsletters
Sign up for the JPT weekly newsletter.
Sign up for the JPT Unconventional Insights monthly newsletter.
President's Column
-
 SPE President Terry Palisch is joined by Paige McCown, SPE senior manager of communication and energy education, to discuss how members can improve the industry’s public image.
SPE President Terry Palisch is joined by Paige McCown, SPE senior manager of communication and energy education, to discuss how members can improve the industry’s public image.
-
 SponsoredExpanding its portfolio of high-tier technologies, TAQA develops a high-performance perforation-plugging patented product.
SponsoredExpanding its portfolio of high-tier technologies, TAQA develops a high-performance perforation-plugging patented product. -
 SponsoredWith almost three-quarters of the global greenhouse gas emissions coming from the energy sector, there is a heavy burden and a huge responsibility on the shoulders of all countries of the world to transform the energy sector to be cleaner and greener by eliminating these emissions.
SponsoredWith almost three-quarters of the global greenhouse gas emissions coming from the energy sector, there is a heavy burden and a huge responsibility on the shoulders of all countries of the world to transform the energy sector to be cleaner and greener by eliminating these emissions. -
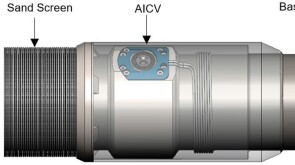
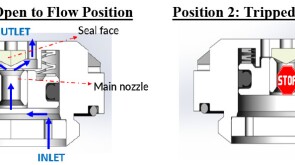 SponsoredSmart completions using autonomous outflow control devices significantly helped in improving reservoir management and increasing oil and gas field productivity by enhancing the injection wells' performance.
SponsoredSmart completions using autonomous outflow control devices significantly helped in improving reservoir management and increasing oil and gas field productivity by enhancing the injection wells' performance. -
 SponsoredWith more surface facilities and infrastructure in oil and gas fields, well casing integrity is becoming an even bigger challenge. This article sheds light on the optimum way to deal with the increasing casing integrity challenges in the Middle East through field monitoring and time-lapse casing-integrity and corrosion-inspection logging.
SponsoredWith more surface facilities and infrastructure in oil and gas fields, well casing integrity is becoming an even bigger challenge. This article sheds light on the optimum way to deal with the increasing casing integrity challenges in the Middle East through field monitoring and time-lapse casing-integrity and corrosion-inspection logging.
Technology Focus








Recommended for You (Login Required for Personalization)

The developer of the recently emerged anchorbit technology is preparing to drill its first geothermal well next year in Germany.

The use of oil-based muds has precluded countless drill cuttings from being used to predict reservoir fluids despite once being part of the reservoir. A 6-decade-old technology may be on the cusp of changing that.

The world's largest oilfield service company made the deal to expand its exposure to the less cyclical production segment of the upstream business.

Blocked by sanctions from obtaining Western technology, Tehran has turned to its domestic service industry to expand production as Chinese demand reaches new highs.
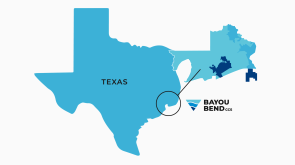
After becoming one of the first US independents to go big on CCS less than 3 years ago, Houston-based Talos Energy is making its exit.

ExxonMobil and Aramco CEOs talk molecules, electrons, and the need to "abandon the fantasy of phasing out oil and gas" at the "Super Bowl of Energy" in Houston.
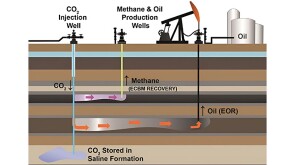
The long, successful history of various metallurgies in EOR wells has been cited as sufficient to allow the same completions for CCS injection wells. The lack of actual data on the long-term performance of these alloys in EOR wells in combination with the more-stringent requirements for Class VI wells suggests otherwise.

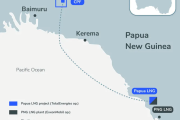
Samsung E&A takes home $6 billion of the total amount as EPC contractor.




-
Texas has become an early hot spot for geothermal energy exploration as scores of former oil industry workers and executives are taking their knowledge to a new energy source.
-
Ignis H2 Energy and Imeco Inter Sarana announced a strategic partnership to expedite geothermal development in Indonesia.
-
One area where the untapped potential of geothermal energy has been realized is in harnessing thermal energy from abandoned or inactive oil and gas wells. Such wells could be exploited for electricity generation or direct use through well repurposing.


Content by Discipline