Every day, reservoir and production engineers are presented with massive streams of real-time data from all kinds of intelligent-field equipment. The existing systems for data cleansing and summary are based on batch processing; hence, engineers find it challenging to make the right decision on time and do not have the capacity to instantly detect interesting patterns as data arrive in streams. This paper addresses the architecture, implementation, and benefits of complex-event processing (CEP) as a solution for the intelligent field.
Introduction
CEP is an innovative, rising technology designed to handle large amounts of data with minimal latency in real time. This technology can aid in the detection of trends and anomalies in the data stream such as unusual buildup or drawdown in well pressure in real time. Furthermore, CEP is an event-driven solution, meaning that it is triggered by events such as changes in downhole pressure in order to perform computational logic to calculate average reservoir pressure. This process will in turn provide reservoir and production engineers with clean -real-time data and notifications of prominent events.
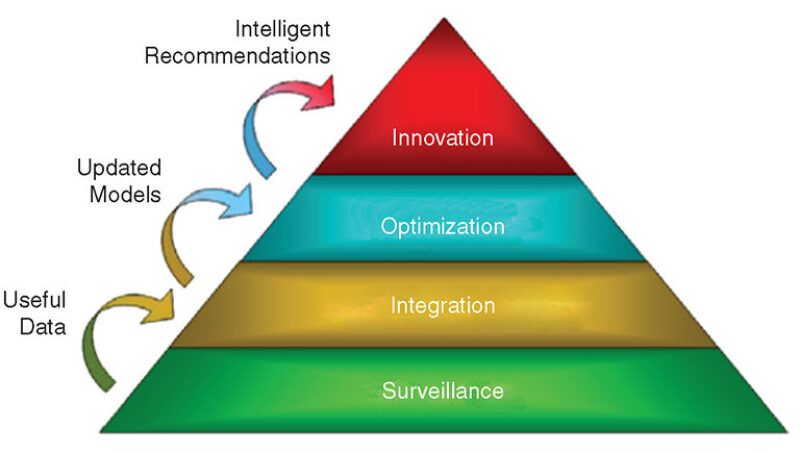
Overview of Intelligent-Field Structure. For the implementation of the intelligent field, Saudi Aramco has adopted a four-layered architecture. These layers are surveillance, integration, optimization, and innovation, as shown in Fig. 1. The surveillance layer is responsible for continuous monitoring of real-time production data and makes use of data-management tools to ensure the validity of the data. The integration layer processes real-time data to detect trends and anomalies. These anomalies are referred to reservoir engineers for analysis and resolution. The optimization layer streamlines field-optimization capabilities and management recommendations. The innovation layer stores event knowledge and triggers optimization processes and actions throughout the field’s life cycle. This final layer captures “intelligence” and injects it into the system.
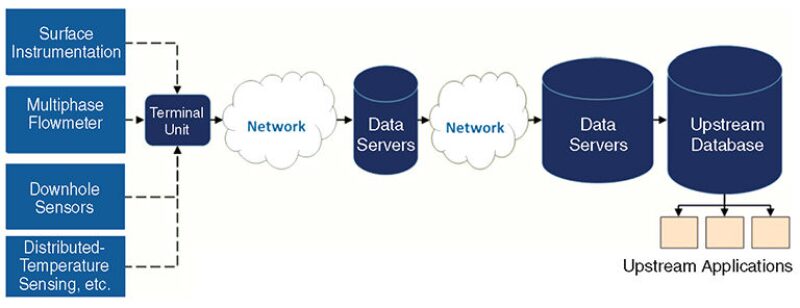
Real-time data traverse multiple zones of instrumentation, networks, and data servers before they reach the corporate database and the engineer’s desktop (Fig. 2). A typical piece of data captured by a sensor will be transmitted automatically from the sensor and will pass through multiple data servers connected through wired/wireless networks. The data eventually reside in the corporate database.
CEP
CEP is the continuous and incremental processing of event streams from multiple sources that is based on a declarative query and pattern specifications, with near-zero latency. CEP has many applications, including the following:
- Web analytics: Click-stream data analysis and analysis of online consumer behavior.
- Power utilities: Power-consumption monitoring.
- Banking services: Detecting anomalies in consuming habits to detect fraudulent behavior.
CEP has received increasing attention in the upstream industry. Studies have explored how CEP can be employed in production optimization and pump-failure detection. To put things into perspective, a comparison of CEP with traditional relational-database technology is warranted.
In traditional databases, a user issues a request for a query and the database sends back the response. Relational-database technology lacks support for temporal analytic capabilities and therefore will struggle with more-complex queries, such as calculating the running hourly average of the pressure every 20 seconds. Such a task would require the use of a scheduled batch job that would run every 20 seconds to calculate the average. This approach suffers from a number of issues. First, it does not scale well; with thousands of wells, the database will be overwhelmed. Second, every new query requires a scheduler, which can cause maintainability issues. Third, scheduling conflicts can arise when complicated queries are used as input to other queries, and this problem can be hard to debug. CEP can resolve these complications through the use of standing queries to process the data.
With CEP, the input stream is constantly processed as a standing query and generated through the output stream. This paradigm shift from the request/response of relational data-bases allows CEP to process data as they arrive from the data source. All event processing is achieved in-memory, and this contributes to the high-throughput, low-latency goal.
Furthermore, CEP is already integrated with temporal analytical capabilities that allow it to perform complex queries such as running averages and real-time pattern detection. For example, CEP has temporal windowing features that allow query builders to specify the period of time used for each window of events. One such window is the hopping window, which defines a subset of events that fall within some period, and over which one can perform a set-based computation such as an aggregation. A window will hop forward by a fixed time period on the basis of two time spans: the hop size H and the window size S. Thus, for every time unit of size H, a window of size S is created.
Architecture. A CEP system comprises three constructs: the event source, the event-processing agent (EPA), and the event sink. The event source is responsible for pushing the data from the source—such as a database or data--generating equipment—to the EPA in a format that is understood by the EPA. The EPA will then process these events coming from the source and perform some computation such as aggregation and/or trend analysis. Once the EPA is finished processing the events, it will push the result toward another EPA for further processing or toward an event sink. The event sink will then consume the results from the EPA and perform any necessary transformations to store it in a database, send an email notification, or even initiate a custom workflow.
The plant-information (PI) system and the upstream database can be considered as data sources. The proposed solution is to push the data in the PI system into the CEP engine and use the upstream databases for fetching configuration information about the sensors, instrumentation, wells, reservoirs, and formations. Input adapters will need to be implemented to transform the data from these two data sources into a format understood by the CEP engine. Afterward, the EPAs come into play. At the moment, there are three EPAs: data cleansing and quality assurance, statistical analysis and normalization, and computation and pattern detection. After processing the data, each EPA will push the results toward the appropriate next-in-line handler, which can be either another EPA or an event sink. The event sinks can have a range of different tasks, such as sending email notifications in the case of an alerting scenario for business-reporting purposes, or even to store the results in the upstream databases for use by other business applications.
Applications. Data Cleansing and Quality Assurance. Engineers rely on clean data to ensure that their decisions can be as accurate as possible. Hence, it is of the highest importance that the data be filtered from erroneous values that can result from faulty instrumentation or from unaccounted randomness. Such filtering can be categorized into two types: single-event cleansing and multiple-event cleansing. The former is filtered solely on the basis of that single event alone, whereas the latter requires multiple events to apply the filtering logic.
Single-event cleansing includes errors such as out-of-range or negative values. By using CEP technology, a standing query can be devised that will filter out-of-range values from the stream and divert those violations to another process.
The removal of other types of invalid values, such as those characterized as stuck, frozen, outliers, or noise, would require multiple events. Consider, for instance, the filtering of stuck or frozen values. To achieve this efficiently using CEP, we would need to compare consecutive events in a tumbling window. The period of this window can vary according to the business need or to the period of acceptance of nonchanging values.
Statistical Analysis and Data Normalization. To ease the extraction of knowledge from the large amount of real-time data coming in, two techniques are applied to use CEP to normalize and simplify the data. One technique is aggregation, applying statistical analysis that allows for the computation of the sums, averages, standard deviations, and regressions. The second technique involves the transformation of individual sensor-measurement-data formats to a more-general well-data format. The transformation will convert tag readings from the sensor identification, time stamp, and value layout to a summarized well layout that includes well identification, time stamp, oil rate, gas rate, water rate, choke position, and bottomhole pressure.
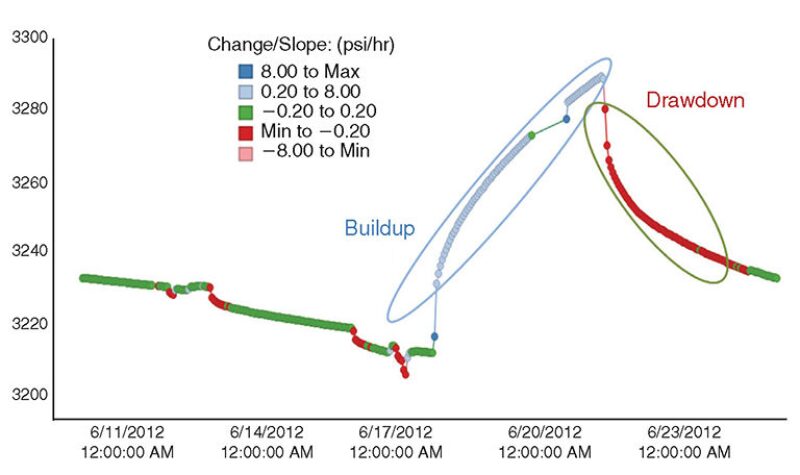
Pattern Detection. Detecting patterns and anomalies in the production environment of wells and reservoirs can be a challenge. Engineers take an interest in a number of events that may arise, such as when the pressure rapidly increases or decreases. An engineer may also want to be alerted when a more-gradual pressure buildup occurs, and will want to know the buildup rate. For this, a report is generated daily to provide the engineer with the pressure-buildup information, but it is not provided in real time. By use of CEP, it is possible to detect such a buildup by calculating the change in pressure over a specified tumbling window. Fig. 3 shows an example of bottomhole-pressure buildup and drawdown during the shut-in period, transient state, and choke-position change over 25 days.
Event-Driven Computation. Event-driven computation is the ability to process data as they arrive, driven by the frequency of the data source. This produces results as soon as, and only when, new input is available, and without any delay or unnecessary duplicate results. One example of event-driven computation is calculating the datum pressure for a well. Because data are coming from different sensors, the first step is to create a data stream for each tag.
A problem that may arise during calculation is that sensors may have different time stamps. The solution for this concern is to convert the point event into a signal event. This will prolong the duration of the point event until the next event time stamp.
This article, written by JPT Technology Editor Chris Carpenter, contains highlights of paper SPE 167817, “Implementation of Complex-Event Processing for the Intelligent Field,” by Muhammad Al-Gosayir, Moayad Al-Nammi, Waleed Awadh, Abdullah Al-Bar, and Nasser Nasser, Saudi Aramco, prepared for the 2014 SPE Intelligent Energy Conference and Exhibition, Utrecht, the Netherlands, 1–3 April. The paper has not been peer reviewed.