Trending Content






The contractor sells rigs and Qatar JV stake to Gulf Drilling International in $338 million deal.

The acquisition of SilverBow Resources gives Crescent Energy a pro forma output of 250,000 BOE/D.

The Norwegian oil company said it may spend more than $130 million to get in on the emerging lithium brine business in Texas and Arkansas.
-
 The agreement puts an early contractual framework in place for closer collaboration sooner on the project pair.
The agreement puts an early contractual framework in place for closer collaboration sooner on the project pair. -
Drillships Deepwater Asgard and Deepwater Atlas have fresh US Gulf Mexico campaigns upcoming that will earn the driller more than $500,000 per day.
-
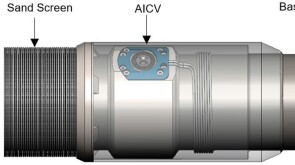
Traditional oil extraction methods hit a snag in noncontiguous fields, where conventional flow-based EOR techniques falter. In southwest Texas, a producer faced imminent shutdown of its canyon sand field due to rapid production decline. Field tests using elastic-wave EOR determined whether the field could be revitalized or if a costly shut-in process was inevitable.



Get JPT articles in your LinkedIn feed and stay current with oil and gas news and technology.

The health, safety, and environment (HSE) discipline is one of the broadest in SPE, from the perspectives of both its scope and its cross-discipline impact. As JPT celebrates 75 years, former HSE Technical Director Roland Moreau examines some of the defining moments in the history of HSE in the industry, the growth of the discipline, and the challenges it still faces.

From the first supercomputer to generative AI, JPT has followed the advancement of digital technology in the petroleum industry. As the steady march of innovation continues, four experts give their views on the state and future of data science in the industry.

There will always be a need for good artificial lift engineers. So, what should the next generation of its professionals be trying to pursue?

Longtime leaders in artificial lift discuss and share their insights on the rapidly evolving segment’s past, present, and future.

The world of artificial lift has witnessed a remarkable revolution over the past 25 years, with many of the events and technology trends recorded in the Journal of Petroleum Technology.

Longtime JPT Technology Editor Dennis Denney discusses his career at SPE and the development of the magazine’s Technology Focus feature.

We’re excited to begin the year with the commemoration of JPT’s 75th anniversary. This issue launches our special features dedicated to JPT’s reporting of technology and practices over the past 7½ decades.

Highlights of innovations in fracturing, drilling, and reservoir engineering include mysterious gummy bears, horseshoe-shaped wells, and automated rigs.

Find out what made the list of big technology breakthroughs that have shaped the oil and gas industry over the past quarter century.

The topics covered in JPT’s Technology Focus feature span the breadth of the upstream industry. A review of these topics over the years illustrates the changes that have affected E&P professionals.
-
 Operators are turning the tide on the Lower Tertiary trend with increasingly large stimulations that are also pushing the limits of offshore technology.
Operators are turning the tide on the Lower Tertiary trend with increasingly large stimulations that are also pushing the limits of offshore technology. -
 The prestigious award celebrates OTC exhibitors who are revolutionizing the industry with their groundbreaking technologies. This year, 15 exceptional technologies—five of which hail from small businesses—were chosen for their advancements. Join us in recognizing these trailblazers who are shaping the future of offshore energy.
The prestigious award celebrates OTC exhibitors who are revolutionizing the industry with their groundbreaking technologies. This year, 15 exceptional technologies—five of which hail from small businesses—were chosen for their advancements. Join us in recognizing these trailblazers who are shaping the future of offshore energy. -
 Matthew Bryant has spent years trying to convince engineers that the API proppant testing standard has significant limitations. And he may well be right.
Matthew Bryant has spent years trying to convince engineers that the API proppant testing standard has significant limitations. And he may well be right. -
 At COP28, more than 50 oil and gas companies took a historic step toward decarbonization by launching the Oil & Gas Decarbonization Charter. This article explores the importance of this effort, the opportunities available to the industry to reduce its Scope 1 and 2 emissions, and the key technologies needed to achieve the net-zero goal.
At COP28, more than 50 oil and gas companies took a historic step toward decarbonization by launching the Oil & Gas Decarbonization Charter. This article explores the importance of this effort, the opportunities available to the industry to reduce its Scope 1 and 2 emissions, and the key technologies needed to achieve the net-zero goal.
Access to JPT Digital/PDF/Issue

Sign Up for JPT Newsletters
Sign up for the JPT weekly newsletter.
Sign up for the JPT Unconventional Insights monthly newsletter.
President's Column
-
 SPE President Terry Palisch is joined by Jennifer Miskimins, department head of petroleum engineering at the Colorado School of Mines, to discuss the academic aspect of petroleum engineering and its future.
SPE President Terry Palisch is joined by Jennifer Miskimins, department head of petroleum engineering at the Colorado School of Mines, to discuss the academic aspect of petroleum engineering and its future.
-
 SponsoredWhich criterion do you rely on to make mutually exclusive decisions: Net Present Value or Rate of Return? When NPV and ROR are not in agreement, you must develop a proper incremental analysis to make the best economic choice.
SponsoredWhich criterion do you rely on to make mutually exclusive decisions: Net Present Value or Rate of Return? When NPV and ROR are not in agreement, you must develop a proper incremental analysis to make the best economic choice. -
 SponsoredThe oil and gas industry makes up 40% of all anthropogenic methane emissions because of leaks at the wellsite. Fortunately, the well pad is often where methane emissions are easiest to address through a mitigation strategy of optimized maintenance and process control—all enabled by instrumentation insight.
SponsoredThe oil and gas industry makes up 40% of all anthropogenic methane emissions because of leaks at the wellsite. Fortunately, the well pad is often where methane emissions are easiest to address through a mitigation strategy of optimized maintenance and process control—all enabled by instrumentation insight. -
 SponsoredExpanding its portfolio of high-tier technologies, TAQA develops a high-performance perforation-plugging patented product.
SponsoredExpanding its portfolio of high-tier technologies, TAQA develops a high-performance perforation-plugging patented product. -
 SponsoredWith almost three-quarters of the global greenhouse gas emissions coming from the energy sector, there is a heavy burden and a huge responsibility on the shoulders of all countries of the world to transform the energy sector to be cleaner and greener by eliminating these emissions.
SponsoredWith almost three-quarters of the global greenhouse gas emissions coming from the energy sector, there is a heavy burden and a huge responsibility on the shoulders of all countries of the world to transform the energy sector to be cleaner and greener by eliminating these emissions.
Technology Focus








Recommended for You (Login Required for Personalization)

The latest signs that momentum is building in the geothermal space include military bases.

Losing drill-hungry independent and private companies in the region to robust M&A will mean an activity slowdown that is expected to impact volumes coming from the nation’s largest oil field.

Dutch leaders have voted to halt all future production from the large gas field due to seismic activity linked to extraction operations.

The geothermal company will use organic Rankine cycle (ORC) technology, which does not require steam to generate electricity.

The second major deal in the US proppant industry this year will see US Silica go forward as a private company.

The Midland-based service company operates a fleet that is now 65% either dual-fuel or electric-powered.

The $6-billion Azeri Central East (ACE) platform is the first BP-operated offshore production facility controlled from onshore.

In the pursuit of sustainable industrial operations, three pivotal objectives emerge: risk reduction, safety assurance, and cost minimization. Integrating these objectives into digital transformation strategies enables operators to effectively manage emissions and achieve success.




-
Texas has become an early hot spot for geothermal energy exploration as scores of former oil industry workers and executives are taking their knowledge to a new energy source.
-
The challenges that geothermal energy faces to become a leading player in the net-zero world are well within the areas of expertise of the SPE community, ranging from rapid technology implementation and learning-by-doing to assure competitiveness to establishing suitable funding mechanisms to secure access to capital.
-
The developer of the recently emerged anchorbit technology is preparing to drill its first geothermal well next year in Germany.



Content by Discipline